

Data processing
A general workflow for data processing methodology can be found in Williams et al. (2012). Key requirements for raw image processing and positional data are as follows:
- It is recommended that at least one of the stereo images is in colour and enhanced following similar procedures as outlined by Bryson et al. (2016).
- All stereo images should be georectified following Williams et al. (2012). If not stereo then processing routines can be found in Morris et al. (2014).
- Positional data should be post-processed using Simultaneous Localisation and Mapping (SLAM) as demonstrated in Barkby et al. (2009) and Palomer et al. (2013)
Data annotation
Scoring of individual images can be done using a number of annotation software tools. Examples include, Transect measure, Coral Point Count, CoralNet and Squidle+. For national consistency, Squidle+ (https://squidle.org) is recommended as it is free and allows for different approaches in image subsampling, which appears to influence inferences from data (Monk et al. unpublished data), as well as stratified and random point count distribution on images. It also automatically imports the collected AUV data once it is uploaded to the AODN making it ready for analysis, and has tools for exploring survey data as well as analysis. In addition, it supports multiple annotation schemes, and will provide consistency through translation between schemes, which is an important point that differentiates Squidle+.
There are three approaches recommended for annotating georeferenced imagery from AUVs:
- Annotation of individual images
- Annotation of photomosaics
- Extracting structural complexity from orthomosaics
A how-to guide about setting up annotation media sets within Squidle+ is provided at https://squidle.org/wiki. Annotation of individual images or photomosaics can be undertaken using three methods:
-
Full assemblage scoring of imagery across space and time. It is important to note that this is a time-consuming process, requiring a lot of replicate images to be scored to enable sufficient power to detect biologically meaningful change as most morphospecies are < 10 % cover within images. This approach appears to be good for delineating bioregional and cross-shelf patterns at a morphospecies (Monk, et al. unpublished data) and CATAMI (Althaus et al. 2015) level (James et al. 2017; Monk et al. 2016). This approach will no doubt be effective in choosing an initial suite of indicators for national level monitoring and reporting.
As a general guideline, and dependent on the survey question, we recommend that 25 random points per image from at least 50 images per transect leg are a good starting point for recording most morphospecies present within images (based on Perkins et al. 2016). It is important to note that the properties of the organisms themselves will also influence the number of points/images to score. Obviously, morphospecies that are less abundant require more effort, but also the ‘clumpiness’ of species will affect the scoring effort needed (Perkins et al. 2016). Van Rein et al. (2011) and Perkins et al. (2016) suggest that, while a higher number of points per image can increase the detection rate of more organisms within an image, increasing the number of scored images using fewer points is likely to have a similar (or greater) effect. Ideally, increasing both the number of images scored and the number of points scored within an image would result in greater power (Roelfsema et al. 2006), but preference is usually for increasing the number of images (Perkins et al. 2016). Unfortunately, the adoption of this approach is likely to result in substantial increases in processing time and thus cost.
-
Targeted scoring of indicators or proxies (such as grouping fine level morphospecies into broader level CATAMI classes; Monk et al. unpublished data). This approach has been shown to work very well at an indicator morphospecies level for detecting change at a regional level (Perkins et al. 2017) as well as for detecting invasive species trends (Ling et al. 2016; Perkins et al. 2015). More recently this approach has been extended to mobile species, such as fish (Seiler et al. 2012) and lobster (Bessell et al. unpublished data). Care needs to be taken if length data (using photogrammetry or structure from motion) is extracted from stereo pairs from Sirius data as both Seiler et al. (2012) and Bessell et al. (unpublished data) found precision can be poor for mobile species if camera separation is inadequate (see Boutros et al. 2015)
Since this approach requires substantially less effort to score each image, more images (i.e. often all images) can be scored and, thus, increased statistical power. The drawback is that narrower understanding of the environment is produced.
-
Automated analysis of imagery potentially provides a cost-effective alternative to annotating imagery from AUVs. It is important to note that automated imagery analysis is a relatively new, and largely developmental, way of annotating images. Despite this some studies suggest that coral and macroalgae can be reliably identified using automated image analysis (Table 7).In 2023, Squidle+ implemented automated annotation tools for the detection of urchins and the classification of Ecklonia radiata, canopy-forming macroalgae, mud/sand, hard-coral, seagrass and sponges.
The last approach to annotating AUV imagery involves the extracting 3D structural information from stereo images using structure from motion techniques outlined in Ferrari et al. (2016) and Pizarro et al. (2017). This approach works particularly well too for sessile species to track changes in growth form through time at a 25 x 25 m scale (Ferrari et al. 2016).
Table 4.1: A brief summary of methods for automated benthic image classification. The number of classes and the main taxa included in the respective studies are also shown.
| Authors | Classes | Main Species |
|---|---|---|
| Marcos et al. (2005) | 3 | Corals |
| Stokes & Deane (2009) | 18 | Corals, Macroalgae |
| Pizarro et al. (2008) | 8 | Corals, Macroalgae |
| Beijbom et al. (2012) | 9 | Corals, Macroalgae |
| Denuelle & Dunbabin (2010) | 2 | Kelp |
| Bewley et al. (2012) | 19 | Corals, Algae and Kelp |
| Bewley et al. (2014) | 19 | Corals, Algae and Kelp |
| Beijbom et al. (2016) | 10 | Corals, Macroalgae |
| Mahmood et al.(2016a) | 9 | Corals, Macroalgae |
| Mahmood et al. (2016b) | 2 | Corals, Macroalgae |
Data curation and quality control
A national AUV steering group has been set up to oversee a nationally coordinated AUV benthic monitoring program which is supported by the Integrated Marine Observing System (IMOS) (Table 4.2). Any new AUV deployments should be discussed with this steering group to ensure that, wherever possible, they can be integrated within the national program [Recommended].
Table 4.2: Key contacts in national AUV steering group as of Jan 2018
| Name | State | Organisation |
| Neville Barrett* | Tasmania | IMAS |
| Craig Johnson | Tasmania | IMAS |
| Jacquomo Monk | Tasmania/Victoria | IMAS |
| Peter Steinberg | New South Wales | SIMS |
| Alan Jordan | New South Wales | NSW DPI |
| Stefan Williams | New South Wales | USyd |
| Gary Kendrick | Western Australia | UWA |
| Russ Babcock | Western Australia | CSIRO |
| Paul Van Ruth | South Australia | SARDI |
| Hugh Sweatman | Queensland | AIMS |
| Tom Bridge | Queensland | JCU/QLD Museum |
| Daniel Ierodiaconou | Victoria | Deakin |
- Chair
Data quality control at both the collection and annotation stage is critical. Most importantly, the annotation schema needs to be consistent between studies. Squidle+ has a built-in QAQC interface to ensure the consistency of annotations with exemplars managed by schema custodians. Morphospecies and associated CATAMI parent classes be used [Recommended]. An initial morphospecies catalogue for southeastern shelf waters is currently held and maintained at the Institute for Marine and Antarctic Studies (IMAS) (contact Dr Neville Barrett or Dr Jacquomo Monk).
Other annotation schemas are available, and can be applied. In such situations where an alternative schema are used to annotate AUV imagery, it must be able to be mapped to CATAMI so that comparisons can be made with previous studies or between regions. Translations between schema can be readily applied within Squidle+.
The quality control of all annotations undertaken by novice scores should be assessed against an experienced analyst (e.g. using confusion matrices; Figure 4.4). Logically, it is important to correct any discrepancies between annotators. This can be done by re-examining the images to ensure an agreement can be reached between annotators. Alternatively, if an agreement cannot be reached, then the miss-classified morphospecies could be potentially grouped into a higher level CATAMI class.
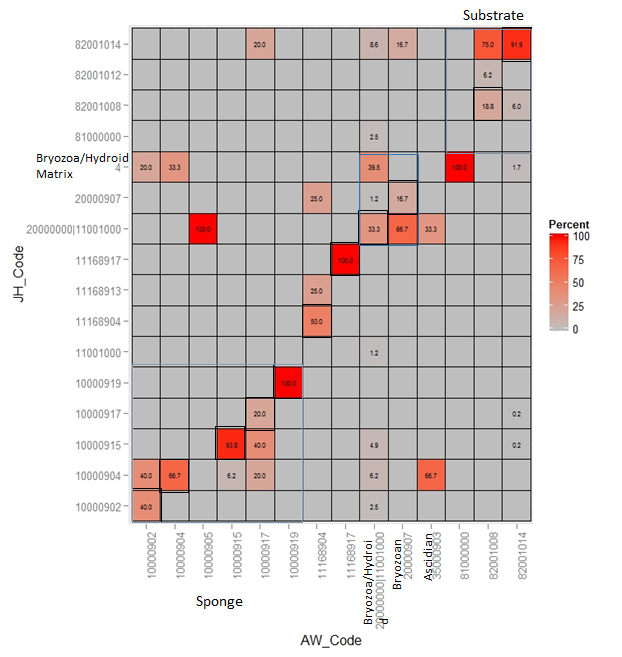
Figure 4.4: Confusion matrix showing the CATAMI classes scored by novice 1 (AW) and experienced (JH) for 30 co-scored images. Black outlined boxes indicate consistent classification between scorers, the percent of all points scored as any particular class are shown in each box and colour-coded. Blue outlined boxes indicate sponge, bryozoan/hydroid and substratum respectively moving from left to right across the image.
Data release
Squidle+ is a centralised online platform for standardised analysis and annotation of georeferenced imagery and video. Many national marine observing programs (for example IMOS through the Australian Ocean Data Network (AODN) or the Marine Geoscience Data System (MGDS) in the USA) routinely store imagery data online in an openly accessible location. Squidle+ operates based on flexible distributed data storage facilities (i.e. imagery can be stored anywhere in an openly accessible online location) to reduce data duplication and inconsistencies, and provides a flexible annotation system with the capability to translate between different annotation schemes.
Following the steps listed below will ensure the timely release of imagery and associated annotation data in a standardised, highly discoverable format.
- Create a metadata record describing the data collection. Provide as much detail as possible on the deployment (either directly in the metadata record itself, or in the form of attached field sheets as .csv, .txt or similar). Details of minimum metadata requirements are provided in Onboard Data Processing and Storage section above.
- Publish metadata record(s) to the Australian Ocean Data Network (AODN) catalogue as soon as possible after metadata has been QC-d. This can be done in one of two ways:
- If metadata from your agency is regularly harvested by the AODN, follow agency-specific protocols for metadata and data release.
- Otherwise, metadata records can be created and submitted via the AODN Data Submission Tool. Note that user registration is required, but this is free and immediate. \
Lodging metadata with AODN in advance of annotation data being available is an important step in documenting the methods and location of acquired imagery and enhancing future discoverability of the data.
- Upload raw imagery from the survey to a secure, publicly accessible online repository (contact AODN if you require assistance in locating a suitable repository).
- Create a Squidle+ campaign as soon as possible after imagery is uploaded, choose the most appropriate annotation schema, and commence annotation of imagery.
- Add links to the location of the Squidle+ campaign to the previously published metadata record. You may also wish to attach or link a copy of the annotation data directly to the record.
- Produce a technical or post-survey report documenting the purpose of the survey, sampling design, sampling locations, sampling equipment specifications, annotation schema (e.g. morphospecies, CATAMI, etc.), whether the survey was assemblage-based or targeted towards key (morpho)species, number of points, interval between images (e.g. every 50th image), and any challenges or limitations encountered. Provide links to this report in all associated metadata. See Appendix C for a suitable template [Recommended].
Data analysis
The breadth of research questions precludes any detailed advice on the analysis of data from AUV transects. However, one common attribute of the image-based data that will have to be contented with for all analyses is spatial proximity. The closeness of images, within and sometimes between transects, means that image data are unlikely to be independent (due to spatial autocorrelation). Yet, this is an assumption that many statistical methods rely upon. The failure to meet this assumption means that the inferences from the statistical analysis may be: (i) over-confident, e.g. having a p-value that is too small; (ii) biased, i.e. the estimates do not reflect the truth; (iii) both, or; (iv) no effect. Obviously, the fourth category is what a researcher hopes for, but it is improbable and must be validated. However, if it is known that the study organism exhibits particularly low autocorrelation then the analysis need not consider it explicitly.
Methods to analyse data, accounting for autocorrelation are available. These include geostatistical models (see Foster et al. 2014 for AUV-based examples). However, in certain situations subsampling images will help (see Mitchell et al. 2017 for a marine based example), but not necessarily alleviate completely. Further, if the study is for a broad area, where transects are small and are well-separated, then amalgamating data to transect level may also be appropriate.